Prompt Engineering Is Dead. Long Live Loop Engineering.
Why the head of Claude Code at Anthropic just signaled the end of the “AI whisperer” era — and what comes next.
The quote that shattered the illusion
A few days ago, a single quote from Boris Cherny — the engineer leading the development of Claude Code at Anthropic — quietly sent shockwaves through the software community.
On a public panel, Cherny pulled back the curtain on how the people who build the world’s most sophisticated coding AI actually work with their own models. What he said didn’t just challenge the status quo — it declared an entire emerging discipline obsolete:
“I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.”
Let that sink in.
The man with both hands on the wheel of the best developer model in the world is telling you he took his hands off the wheel. He doesn’t sit in a chat window crafting the perfect paragraph of instructions. He writes code that forces the AI to talk to itself, judge its own mistakes, and fix them inside a closed, autonomous circuit. He builds the machine that steers the model — and then he lets it drive.
If you’re still spending your days fine-tuning prompts to coax the right block of code out of an LLM, his message is brutally clear: you’re optimizing a world that is already gone.
The paradigm shift: from micromanagement to system architecture
To see why this is a tectonic shift, look at how our relationship with generative AI has evolved in just a couple of years.
Phase 1 — The linear prompt (the human bottleneck)
Until recently, the whole industry was obsessed with prompt engineering. We treated LLMs like brilliant but easily-distracted junior developers. The workflow was linear, fragile and entirely manual:
you prompt ─▶ AI writes code ─▶ you find the bug ─▶ you fix the prompt ─┐
▲ │
└───────────────────────── by hand, again ◀─────────────────────────────┘In this paradigm, the human is the bottleneck. You write a prompt, read the output, spot a syntax error, paste it back into the chat, and pray the model hasn’t forgotten the context five steps later. It feels productive. It is exhausting, unscalable micromanagement — and it absolutely cannot run while you sleep.
Phase 2 — Loop engineering (the autonomous circuit)
What Cherny is describing is loop engineering — agentic workflows where the human steps out of the execution loop entirely. You stop driving the car. You build the track, and let the machine run the laps.
Instead of writing a prompt to solve a problem, you write a programmatic loop that embeds the AI inside an automated cycle of execution and verification:
- The goal. A human sets one high-level objective — “build this API endpoint and reach 98% test coverage.”
- The action. The AI generates a first draft of the code.
- The verification. An automated environment — compilers, linters, unit tests, your CI — runs the code and catches every error.
- The self-correction. On a failure, the system captures the stack trace, feeds it back to the AI as a fresh instruction, and orders it to try again.
you set the goal
│
▼
AI writes code ─▶ CI runs every check ─▶ green? ─▶ ✦ shipped
▲ │
│ ▼ (red)
└── AI reads the logs and re-prompts itselfThe loop runs at machine speed, churning through dozens of iterations, self-correcting and self-healing until the verification criteria are met. You never typed a single follow-up. You didn’t write the prompts — you built the track, and the model ran every lap by itself.
The real skill isn’t writing code. It’s writing the judge.
Here’s the part almost everyone misses — and it’s the whole game. The hard part of a loop is not generating the code. Models are already frighteningly good at that. The hard part is the thing that decides whether the code is any good.
Give the loop a strong, ruthless verifier — real tests, static analysis, a compiler that refuses to lie — and it converges on something that genuinely works. Give it a weak one, and that exact same loop will cheerfully produce an infinite river of confident, beautifully-formatted garbage, hallucinating its way to a green checkmark that means nothing.
So the skill of the next decade isn’t prompt-craft. It’s designing the verification — the bulletproof validation systems that let an AI safely talk to itself without driving off a cliff. That’s a harder, rarer and far more valuable kind of engineering than finding the right words.
From philosophy to production: how we architected the loop
While the rest of the tech world breaks down Cherny’s quote on social media, the real challenge is unglamorous: how do you build loop-engineering infrastructure that actually works in production — outside Anthropic’s internal labs?
Close a loop around a single model and you hit the real-world walls fast: context-window degradation, hallucinatory death spirals, and no memory across a project. At Fractera, we spent the last year treating Cherny’s philosophy not as a prediction but as an architectural blueprint — and built the Fractera Development Loop to survive exactly those failure modes.
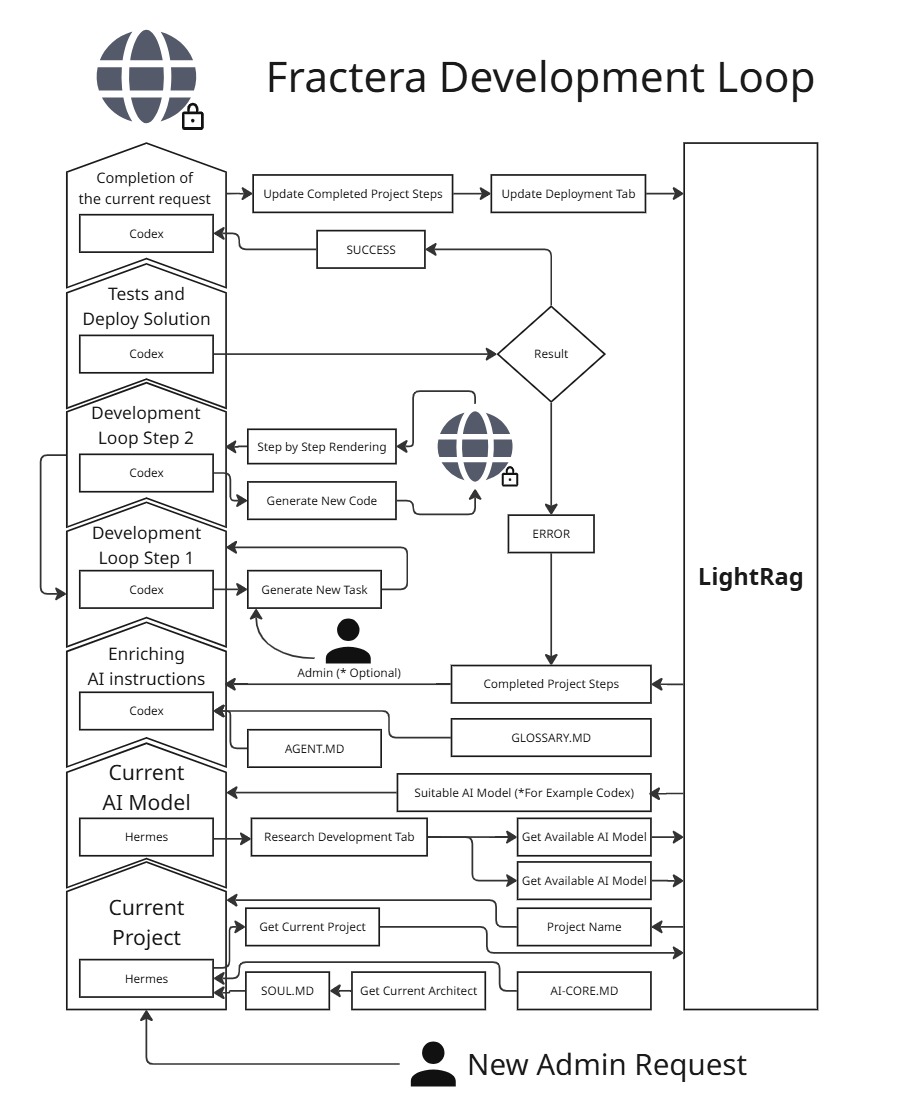
The anatomy of a production-grade loop
To make loops viable for real software, you have to evolve past one AI talking to itself. You need orchestration, specialized agents, and a persistent memory spine:
- Multi-agent orchestration (Hermes). Instead of looping a single model forever, our orchestrator breaks down the high-level command and dispatches the best agent for each micro-task — Claude Code for hard logic, Codex for refactoring, Gemini for fast exploration.
- A graph-memory spine (LightRAG). The biggest risk in an autonomous loop is the amnesia effect: loop fifteen times on a stubborn bug and the agent loses sight of the global architecture. A Knowledge Graph RAG acts as a continuous, un-wipeable memory so every looping agent keeps cross-referencing your codebase’s real rules and style.
- An immutable verification loop. The loop only terminates when the test-and-deploy suite returns zero errors. If a deployment fails, the logs are instantly contextualized by graph memory and thrown back into the agent ring for an automatic cure.
The software engineer’s new job description
We’re moving away from writing code, past writing prompts, and straight into building cognitive pipelines. The craft is no longer the instruction — it’s the system the instruction runs inside.
And it isn’t free. Two new costs arrive with the loops. Comprehension debt: when an agent writes and rewrites a file three hundred times behind the scenes, your grasp of your own codebase quietly erodes — it works, you’re just no longer sure why. And raw compute: a loop can burn real money in tokens chasing one bug across a hundred silent attempts. The engineers who win this era treat cost-versus-quality as a deliberate design decision, not a surprise on the invoice.
Want to look under the hood — the orchestration, the graph memory, and the build-test-correct cycle, in rigorous engineering detail?
Dive into the anatomy of autonomous AI loopsThe era of prompt engineering is officially behind us. The only question left is the one Cherny already answered for himself: are you still trying to talk to your AI — or are you building the loops that let it run?
Source: a widely-shared LinkedIn post by Guillermo Flor surfacing Boris Cherny’s remarks. The quote is reproduced as it circulated; the architecture and the analysis are Fractera’s own.
Frequently asked questions
- What is "loop engineering" and why is it replacing prompt engineering?
- Loop engineering means writing automated workflows that prompt the AI, run its output through a verifier (tests, CI, a compiler), feed failures back as new instructions, and repeat — until the result is correct. Boris Cherny, who leads Claude Code at Anthropic, said he no longer crafts prompts by hand: he writes the loops that do it for him. The key insight is that the bottleneck was never the prompt — it was the human in the feedback cycle.
- How does Fractera implement the agentic development loop in production?
- Fractera runs Hermes as the orchestrator: it reads project context from LightRAG graph memory, picks the right coding agent (Claude Code, Codex, Gemini, Qwen, or Kimi) for each task, hands it a grounded context set, and loops on the build result — feeding errors back as new tasks until the code is green and deployed. The outcome is recorded in LightRAG so every subsequent loop starts smarter.
- Do I need to write code to run the autonomous development loop with Fractera?
- No. You describe the goal in natural language — through the Hermes chat inside your workspace or from Telegram. Hermes turns that into a concrete coding task, picks the best agent, and runs the loop. You watch the project take shape in real time; no code is written by you.