Fractera · the Next.js Aircraft Carrier
The Next.js Aircraft Carrier: Pre-Built Enterprise Boilerplate Deployed in 1 Click
This page is for the skeptic: the developer who suspects a 50,000-line framework is overkill and just another AI token-burner. It is the opposite — a production-ready Next.js starterthat ships the moment you deploy and turns parallel routing into something an AI rotates like a Rubik’s Cube. See also the token economics, the workspace architecture and the development loop, or go back to fractera.ai.
Preventing AI Context Window Inflation
Let us meet the objection directly: *"50,000 lines of code is overkill — and surely it just burns more AI tokens."* The opposite is true, and here is the mechanism.
The real cost driver in AI-assisted development is not the size of the codebase — it is context window inflation. An agent that scans the directory tree, reads hundreds of lines to find where to insert code, and rewrites half a file pays for all of that on every pass, and the bill compounds. This is the cost-effective AI development problem nobody priced in.
Fractera removes that work. Because roughly 99% of the architecture is already written and verified — parallel routing, i18n, production SEO, database, auth — the agent never re-invents or re-reads the infrastructure. To ship a feature it processes a few lines of clean business logic, not the whole framework. The 50,000 lines are not a bill; they are prepaid stability — an armored shield for your token budget and the core of AI code generation cost optimization.
What Parallel Routing Is — and Why the Next Generation of Apps Needs It
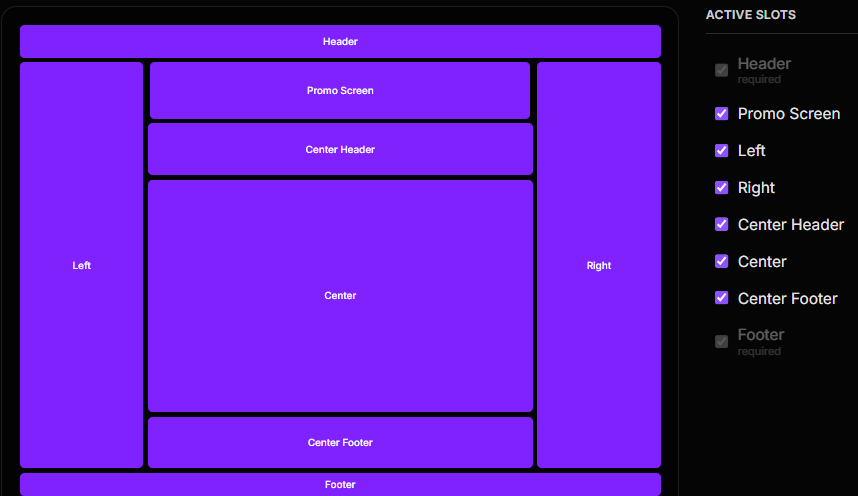
Parallel routing is a Next.js capability built so that, within a single URL — effectively a single screen — a person, an architect, or an AI model can combine a large number of dynamic parts called slots. Some are fixed in place; others appear on demand — as drawers sliding in from the left, right, top or bottom, or as modal windows flashing up in the centre. Most of this happens without changing the main route, without a page reload, and without losing any content.
Under the hood Next.js manages application memory and error handling so robustly that if one tab fails, the maximum damage is the loss of that single tab until it is reopened — the application keeps working. It is an exceptionally reliable model, and it is where the web is heading. Done right, this is also how you win next js parallel routing SEO: every slot is real, crawlable HTML.
Next.js Parallel Routing & On-Demand ISR for Infinite Scale
An AI agent trained to create and activate parallel-routing slots gains the ability to model an interface at an almost limitless level. The Rubik's Cube analogy is even clearer here: instead of letting a project scatter global blocks of content and logic across unpredictable parts of the app, parallel routing structures the core of the Next.js project and lays down the rails that every future page deployment runs along.
Note the word *deployment* rather than *generation*. Backed by on-demand ISR (Incremental Static Regeneration), the framework regenerates thousands of pages without overloading the server or the AI — the foundation of genuinely scalable web application architecture and excellent Next.js App Router performance and Core Web Vitals.
Deployment, Not Generation
Inside each section there are strictly regulated rules for creating content and design, described by the design system. That means the model simply selects the section it needs and passes the required data into it. For this, code generation is barely needed — it is a choice among available options, not authorship from scratch.
These are immutable code patterns: compiled, verified building blocks an AI agent configures but cannot accidentally break. You get the flexibility of custom assembly with the reliability of an enterprise backend.
When Code Generation Kicks In — and Becomes a Reusable Widget
Code generation switches on only at one moment: when the architect decides to add a new section or a new technical, tooling solution. At that point generation runs once and turns the result into a reusable widget the application will use again and again — with no further generation.
So generation is the exception, not the loop. The default path is selection and configuration; authorship happens once and is then frozen into a reusable part.
The Fractera Widget Marketplace
Architects on Fractera will not only create their own widgets but also find them in the Fractera marketplace (coming soon). There, developers can sell their own widget — anything from an AI chat to something far more involved, such as a calculator for the made-to-order price of a fitted kitchen. Architects place these widgets in the marketplace and then attach them to one of their routes.
This is also where MCP server development layout comes in: the AI manages structure and layout — adding, moving, and wiring widgets — through the Model Context Protocol, like turning a Rubik's Cube.
Why There Are So Few Parallel-Routing Examples
There is a simple reason the web has so few real parallel-routing implementations: the technology is too complex for today's AI and demands deep, reliable reference examples. In understanding and in building it, developers run into the fact that parallel routing simultaneously requires a deep grasp of how content is stored, delivered, reused, and refreshed.
In production this matters enormously. A small mistake can flip a project from static generation into dynamic generation, which triggers an instant, avalanche-like spike in server load and an uncontrolled volume of database calls — inflating either your cloud-database bill or your own resource usage.
How Fractera Solved It
With Fractera this does not happen. Before you ever received this offer, Fractera spent a year testing and refining the interaction between parallel-routing slots — so that you receive an application you do not need to *develop*, only to fill with data and parameters.
We also taught the AI model, through several dedicated MCP connectors, to combine all the necessary slots on a single URL — and to change them when needed — in answer to any question from you or your visitor. It is an extraordinary bridge to the future that Fractera hopes will permanently change how applications are built. This is what makes it real high-traffic web infrastructure, self-hosted on hardware you control.
A Self-Hosted Alternative to Vercel for High-Traffic Web Infrastructure
Because the whole stack runs on your own VPS, Fractera is a self-hosted alternative to Vercel: the same one-click deploy speed, none of the per-request pricing that escalates under real-world traffic. Your database, file storage, auth, and the entire parallel-routing framework live on one server, billed once through your VPS provider.
For high-traffic projects this is the difference between predictable infrastructure cost and a bill that scales with every visitor.
Why 50,000+ Lines — and What You Can Build With Them
This is the largest Next.js starter we know of — and the size is the point. 50,000 lines of code so your offer generates new pages in seconds without spending tokens; so you can build dozens, hundreds, or a thousand applications; so you can run many projects on one server — for yourself, for work, for family — to manage business processes and staff, whatever you wish, all in one interactive screen.
Multi-language routing is already wired into those 50,000 lines and works out of the box, so Next.js multi-language routing is a solved, routine problem rather than a project of its own. And the stronger AI models become, the more extraordinary the applications you will build — bringing the Tony Stark and Jarvis era a little closer each year.
What's Inside — and What's Coming
This page is the tip of the iceberg. It will grow into a detailed catalogue — more than a hundred screenshots, each describing one feature, plugin, or widget of the parallel-routing system.
For now, see the live system this runs inside on the AI Workspace architecture page, read how a request becomes shipped software on the AI Development Loop, or understand the cost model on the Token Economics page. When you are ready, deploy the whole stack to your own VPS in about ten minutes.
Want this framework on your own server?
Deploy the whole stack to your own VPS in about 10 minutes — one click, no configuration.
Frequently asked questions
- What is the "Next.js Aircraft Carrier" in Fractera?
- It is a fully pre-built, parallel-routing Next.js application (around 50,000 lines) that ships the moment you deploy Fractera. Eight layout slots (Header, Footer, Left, Right, Center, Promo Screen, Center Header, Center Footer) can be toggled on or off without page reloads, and AI agents can reconfigure the entire layout without human intervention.
- Does the parallel-routing framework hurt AI token efficiency?
- No — it saves tokens. Each slot is a discrete file with a clear, predictable boundary. An AI agent opens, reads, or rewrites exactly the slot it needs without touching the rest of the layout. That is the opposite of a monolithic page where the agent must parse thousands of unrelated lines to change one section.
- Can I use this boilerplate without Fractera's platform?
- The framework is open-source (MIT). You can run it on any Node.js host. Fractera adds the AI development loop, LightRAG memory, Hermes orchestration, and a one-click VPS deploy on top — so the same codebase you get as a standalone starter runs with full AI-native tooling inside Fractera.