Архитектура контентного движка: ликвидация центральных репозиториев
Техническая архитектура изолированного размещения страниц во Fractera. Узнайте, как независимые папки страниц заменяют центральные реестры, снижают расход токенов ИИ и работают как единая дизайн-система.
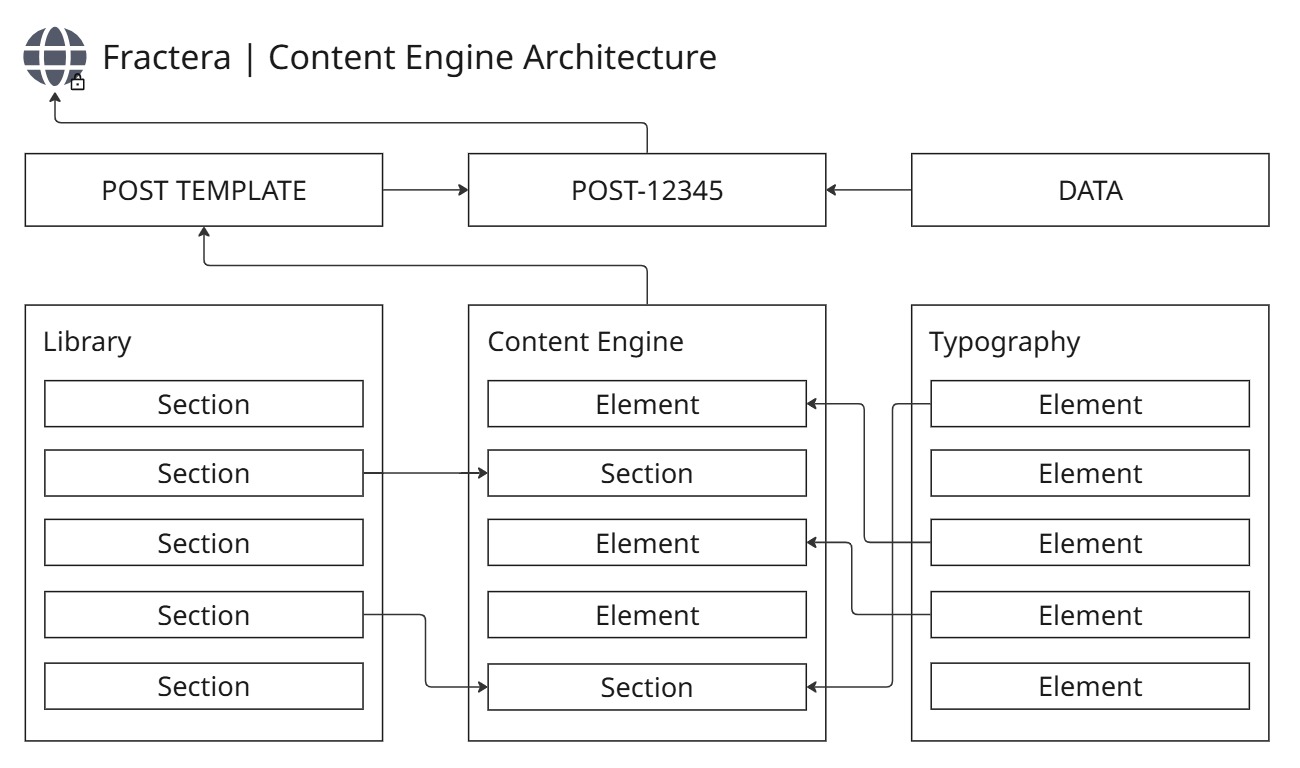
Это руководство детально описывает контентный движок, на котором работают все публичные каналы Fractera — включая новости, блоги и документацию. Наша цель — максимальное упрощение структуры. Разделяя данные и логику маршрутизации, мы позволяем как ИИ-агенту, так и живому разработчику создавать, обновлять или полностью удалять сотую страницу так же безопасно и дешево, как и самую первую.
Базовая архитектура: почему важна изоляция папок
Обычные веб-фреймворки распределяют три ключевые задачи контента по разным местам проекта: хранение сырых данных, отрисовка интерфейса и ведение главного списка страниц. Привязка этих задач к единому глобальному скрипту маршрутизатора или массивному файлу общих типов вынуждает ваши инструменты разработки парсить тонны чужого кода ради изменения одной строчки текста. Fractera вводит жесткое правило изоляции: всё, что нужно конкретной странице для успешной компиляции, живет строго внутри её собственной директории.
Узкие места, которые мы устранили
Создав изолированные папки страниц, этот движок раз и навсегда решает три классические проблемы масштабирования:
- Раздувание монолитного кода: Страницы больше не превращаются в гигантские нечитаемые файлы, так как каждый документ имеет собственную закрытую папку.
- Поключевой перевод: Мультиязычные локализации работают как легковесные файлы переопределения метаданных, позволяя переводить отдельные поля без дублирования верстки.
- Устаревание ручных индексов: Вам больше не нужно обновлять списки страниц вручную. Платформа сканирует директории и автоматически генерирует навигацию при каждой сборке проекта.
Архитектура папок: структура изолированных директорий
Главный контентный хаб (например, блог) представляет собой неглубокий контейнер маршрутизации, под которым находятся папки конкретных публикаций. Каждый документ строго разделяет свой код на три функциональные папки, что делает структуру прозрачной с первого взгляда:
app/[lang]/blog/ ← Главный контентный хаб (Общий контейнер)
page.tsx Тонкий маршрутизатор — экспортирует только индексный вид
_components/ СЛОЙ ПРЕДСТАВЛЕНИЯ — Визуальный дизайн и верстка
index.tsx Шаблон списка публикаций
_lib/ СЛОЙ ЛОГИКИ — Функции, хелперы и контракты типов
post.ts Логика разрешения данных и поиска
types.ts Явные типы, соответствующие данному хабу
_data/ СЛОЙ ДАННЫХ — Локализованные строки интерфейса
en.ts Тексты для базового английского языка
ru.ts Локализованное русское переопределение
index.ts Открытый API-хук доступа: getBlogUi(lang)
_list.generated.ts СЛОЙ АВТОМАТИЗАЦИИ — Создается автоматически при сборке
the-end-of-prompt-engineering/ ← Изолированный документ (Одна публикация = Одна папка)
page.tsx Тонкая ссылка на экспорт файла
_components/index.tsx Модуль композиции: createContentPost({ ... })
_data/ Сырые файлы контента страницы
meta.ts Неизменяемые маркеры: slug, даты, теги индексации
en.ts Основной блок контента на базовом языке
index.ts Экспортер контракта данных: { meta, en, overrides }Чтобы добавить новую страницу, вы просто создаете новую папку. Чтобы полностью стереть страницу, вы удаляете её директорию. Это гарантирует, что в репозитории не останется забытых «файлов-сирот» или сломанных путей импорта.
Сокращение времени на разработку и деплой
С Fractera добавление контента перестаёт быть сложной задачей для DevOps. Здесь нет центральных таблиц маршрутизации, которые нужно обновлять, нет общих модулей типов и ручных индексов. Вы копируете соседнюю папку, меняете внутри нее файлы данных и отдаете проект компилятору. Критически важные компоненты — включая SEO-метатеги, цепочки хлебных крошек, оглавление страницы и разметку данных — применяются автоматически нашими фабриками страниц.
Оптимизация цикла разработки под ИИ-агентов
Разделение кода на данные, верстку и логику создает четкую карту для роботов. Нужно изменить текст? Откройте `_data`. Настроить отступы в верстке? Откройте `_components`. Обновить функциональные параметры? Откройте `_lib`. Поскольку роли файлов жестко определены их папками, ни разработчики, ни ИИ-агенты не тратят время на блуждание по дереву репозитория.
Главный выигрыш: тотальная экономия токенов
Стоимость работы ИИ-агента напрямую зависит от того, сколько строк кода он должен прочитать в свое контекстное окно для безопасного выполнения задачи. Fractera ставит жесткие границы вокруг этого контекста, приумножая вашу экономию по мере роста проекта:
- Ограниченный масштаб: Изменение одной страницы заставляет агента открыть одну изолированную папку, сохраняя рабочую область локальной и предсказуемой.
- Ноль затрат на чтение реестров: Поскольку поиск страниц происходит автоматически при сборке, агенты никогда не тратят токены на чтение и сверку центральной базы маршрутов.
- Единая семантика дизайна: Общий для всего проекта каталог блоков означает, что моделям не нужно заучивать дублирующие интерфейсы или вариации типов для разных страниц.
- Точечное исполнение: Четкое разделение данных и логики избавляет от сканирования директорий, позволяя ИИ тратить бюджет токенов исключительно на выполнение задачи.
Старые кодовые базы обычно затягивают в контекст ИИ множество взаимосвязанных файлов и глобальных конфигураций ради изменения одной кнопки — впустую сжигая тысячи строк входных токенов. Fractera ограничивает доступ строго целевой папкой. Количество затронутых строк падает до минимума, гарантируя, что архитектура окупает себя при каждом запуске ИИ-инструментов.
Структурная дизайн-система
Контент страниц здесь никогда не обрабатывается как свободный, невалидный HTML-код. Вместо этого он собирается как упорядоченный массив строго типизированных блоков: заголовков, цитат, стандартных абзацев, изображений, коллаутов и сеток. Каждый конкретный тип блока ссылается на один глобальный рендерер в общем каталоге проекта. Если вы захотите изменить внешний вид цитат во всем проекте, вы меняете один этот компонент — мгновенно обновляя тысячи живых страниц без ручного рефакторинга.

Стратегия — это создание предсказуемых состояний системы. Мы закладываем прочный фундамент кода для того, чтобы каждое следующее действие умножало скорость нашей разработки и минимизировало затраты на поддержку.
 Roma ArmstrongFounder at Fractera.ai
Roma ArmstrongFounder at Fractera.aiЧастые вопросы
- Как именно такая структура папок защищает контекстное окно ИИ от инфляции?
- За счет ограничения области работы агента изолированными папками. Чтобы создать или изменить страницу, ИИ открывает одну конкретную директорию вместо чтения огромной глобальной библиотеки или изменения центрального индекса маршрутов. Это предотвращает лишние циклы анализа кода и снижает затраты на токены до минимума.
- Почему это считается единой дизайн-системой, а не просто набором шаблонов?
- Потому что данные страниц пишутся в виде структурированных, типизированных блоков кода, а не сырого текста. Каждый блок указывает на один общий компонент рендеринга. Изменение этого компонента автоматически и единообразно обновляет визуальный слой на тысячах страниц без прямого изменения их файлов.
- Что происходит со скоростью компиляции проекта при добавлении сотен страниц?
- Скорость остается стабильно высокой. Каждая новая страница является изолированной папкой, которую наш сканер собирает на этапе компиляции. Глобальные реестры не затрагиваются, языковые версии работают как легкие переопределения ключей, а нагрузка на сервер не растет вместе с объемом контента.